
티스토리 뷰
시험에 자주 나오는 헷갈릴 수 있는 유형을 정리해봤습니다.
● 식별자 관계 ★★
 |
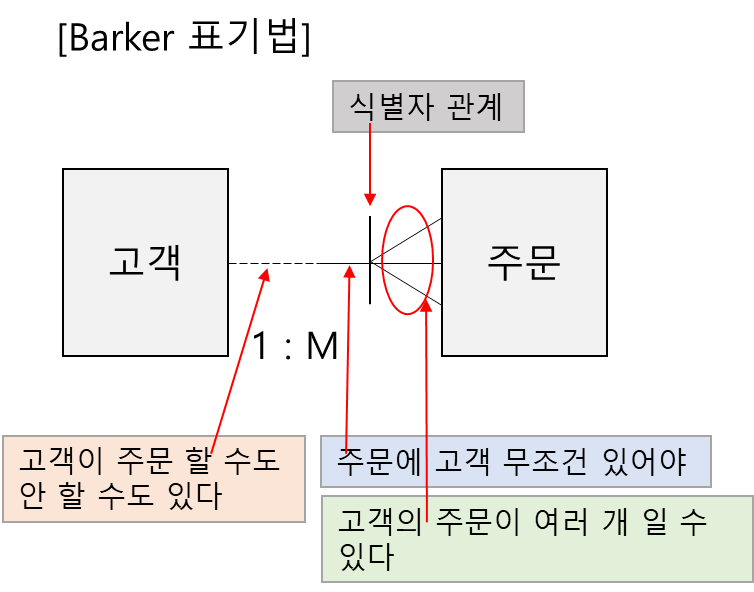 |
● 특징 구분짓기 ★
주식별자
유일성 : 구분가능한 고유값을 가짐
최소성 : 하나의 속성 값만을 가짐
불변성 : 한 번 지정된 값 변경 불가
존재성 : 무조건 값이 존재. Not Null
트랜잭션
ACID
원자성 Atomicity : 반영하거나 아예 반영하지 않거나. All or Nothing
일관성 Consitency : 작업 처리 결과에 일관성 유지 (동일속성)
독립성 Isolation : 다른 트랜잭션이 끼어들 수 없음
지속성 Durability : 트랜잭션 성공 이후, 결과 영구적 반영
● Sum, Count 결과값 맞히기 ★★
--Oracle : [FROM DUAL] 포함
WITH sqld (col) AS (
SELECT 1 [FROM DUAL]
UNION ALL
SELECT 2 [FROM DUAL]
UNION ALL
SELECT 3 [FROM DUAL]
UNION ALL
SELECT NULL [FROM DUAL]
)
SELECT
SUM(COL) AS SUM_COL, -- NULL 제외
COUNT(*) AS CNT_ALL, -- NULL 포함 ★
COUNT(COL) AS CNT_COL -- NULL 제외
FROM sqld;| SUM_COL | CNT_ALL | CNT_COL |
| 6 | 4 | 3 |
● Floor, Ceil, Round 반올림, 내림 ★★
/*
Floor는 바닥이니까 무조건 보다 작은 정수로 반환
Ceil은 천장이니까 무조건 보다 큰 정수로 반환
*/
--ORACLE
SELECT
FLOOR(123.56) AS F_PLUS, FLOOR(-123.56) AS F_MINUS,
CEIL(123.56) AS C_PLUS, CEIL(-123.56) AS C_MINUS
FROM DUAL;
--SQL SERVER
SELECT
FLOOR(123.56) AS F_PLUS, FLOOR(-123.56) AS F_MINUS,
CEILING(123.56) AS C_PLUS, CEILING(-123.56) AS C_MINUS| F_PLUS | F_MINUS | C_PLUS | C_MINUS |
| 123 | -123 | 123 | -123 |
SELECT
ROUND(123.45) AS R0, --소수점 제외하고 표현, 소수점 단위 5 미만 소거
ROUND(123.56) AS R1, --소수점 제외하고 표현, 소수점 단위 5 이상 반올림
ROUND(123.56, 1) AS R2, --소수점 첫째자리까지 표현, 나머지 소수점 둘 째 자리 5 이상 반올림
ROUND(123.56, 2) AS R3, --소수점 둘째자리까지 표현, 나머지 없음
ROUND(123.56, -1) AS R4, --소수점 반대방향으로 1칸 만큼 소거하여 0처리
ROUND(123.56, -2) AS R5 --소수점 반대방향으로 2칸 만큼 소거하여 0 처리
FROM DUAL;| R0 | R1 | R2 | R3 | R4 | R5 |
| 123 | 124 | 123.6 | 123.56 | 120 | 100 |
● 계층형쿼리 Start with ~ Connect by ★★★
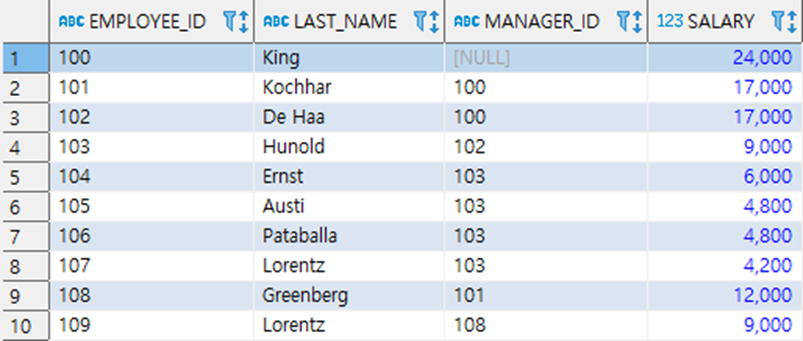
SELECT * FROM EMPLOYEES
START WITH MANAGER_ID IS NULL
CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID;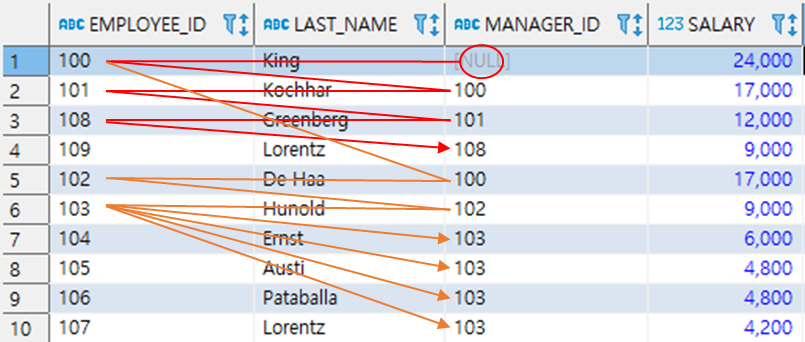
SELECT * FROM EMPLOYEES
START WITH MANAGER_ID = 100
CONNECT BY EMPLOYEE_ID = PRIOR MANAGER_ID;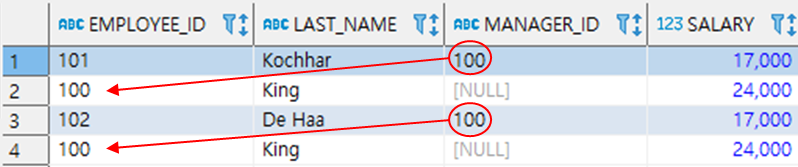
SELECT * FROM EMPLOYEES
WHERE MANAGER_ID <> '103'
START WITH MANAGER_ID IS NULL
CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID;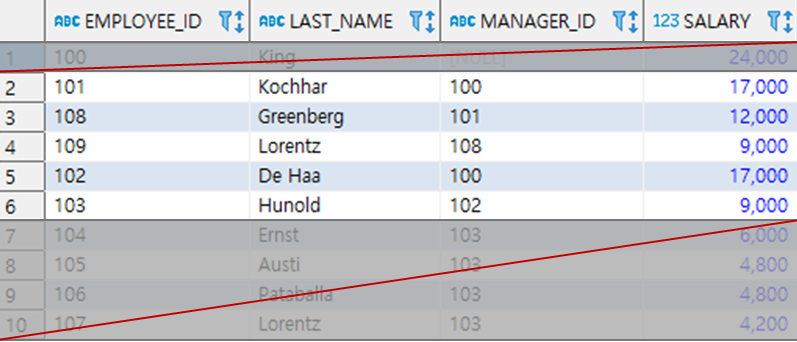
조건절 삽입 시 Start with ~ Connect by 절 수행 이후 Where 절 수행.
비교연산자로 인해 Null 아닌 값이 있는 것 중 ★
MANAGER_ID가 '103' 이 아닌 것 조회
● 윈도우함수 Window Function (Rows/Range, Unbounded Preceding, Following, Current Row) ★★★★★
(최다 기출 유형. 제일 헷갈리면서도 복잡한 내용. 여기서 합/불 여부가 갈림)
숫자/Unbounded Preceding
Rows : 1개 행
SELECT EMPLOYEE_ID, LAST_NAME, MANAGER_ID, SALARY,
SUM(SALARY) OVER(PARTITION BY MANAGER_ID ORDER BY SALARY ROWS UNBOUNDED PRECEDING) AS SAL_SUM
FROM EMPLOYEES;
Range : 어떤 기준에 해당하는 것을 하나로 보는 묶음 단위
SELECT EMPLOYEE_ID, LAST_NAME, MANAGER_ID, SALARY,
SUM(SALARY) OVER(PARTITION BY MANAGER_ID ORDER BY SALARY RANGE UNBOUNDED PRECEDING) AS SAL_SUM
FROM EMPLOYEES;
Patition by Manager_ID : Manager_ID 별로 묶고
Order by Salary : Salary를 정렬하는데
Rows/Range : 하나의 Row 만큼/같은 Salary 의 Range 를 한 묶음으로 범위 지정하여
숫자/Unbounded : 숫자만큼/무한정
Preceding : (첫 번 째의 경우 자기 자신) 선행하는 것을 가져온다.
Current Row
--* 이 경우, Rows current Row 는 자기 자신이므로 생략
SELECT EMPLOYEE_ID, LAST_NAME, MANAGER_ID, SALARY,
sum(SALARY) OVER(PARTITION BY MANAGER_ID ORDER BY SALARY RANGE CURRENT ROW) AS SAL_SUM
FROM EMPLOYEES;
Order by Salary : Salary를 정렬하는데
Range : 같은 Salary는 한 묶음으로 보고
Current Row : 현재 진행되는 상태까지.
=> 같은 것 끼리만 묶이게 됨.
Between A and B 구문을 사용하는 경우
--* 이 경우, Range 도 같은 범위이므로 생략
SELECT EMPLOYEE_ID, LAST_NAME, MANAGER_ID, SALARY,
SUM(SALARY) OVER(PARTITION BY MANAGER_ID ORDER BY SALARY
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS SAL_SUM
FROM EMPLOYEES;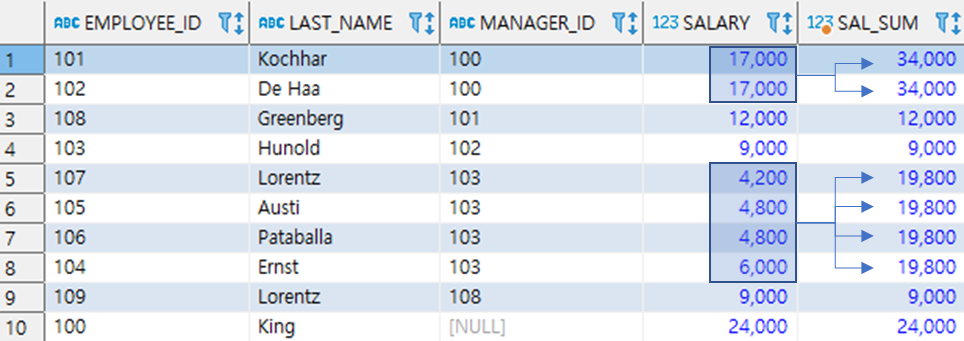
Salary 를 기준으로 Row 단위로 선행하는 것과 후행하는 것을 모두 가져옴
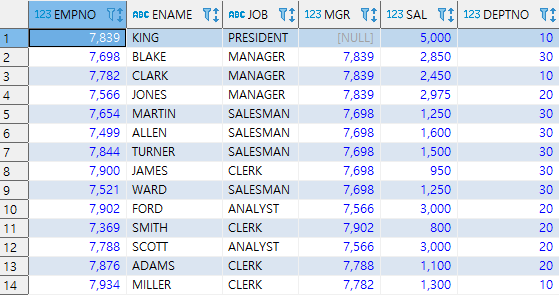
● 그룹 함수 Grouping Function (Roll up, Cube, Grouping Sets) ★★★★
(윈도우 함수와 쌍벽을 이루는 빈출 유형)
 |
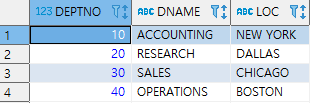 |
Roll up
SELECT b.DNAME, a.JOB, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY ROLLUP(b.DNAME, a.JOB)
ORDER BY DNAME, JOB;
Roll up의 첫 번 째 인수를 기준으로 한 소계를 보여준다. 마지막 인수는 Null로 표기.
그리고 마지막 행에 전체 합계 표시.
다음 쿼리를 풀어서 하면
SELECT * FROM (
SELECT b.DNAME, a.JOB, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY b.DNAME, a.JOB
UNION ALL
SELECT b.DNAME, NULL, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY b.DNAME
UNION ALL
SELECT NULL, NULL, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
)
ORDER BY DNAME, JOB;
/*
SQL Server는 Null값을 가장 작은 값으로 뽑기 때문에 총계가 먼저 오는 문제로
ORDER BY CASE WHEN b.DNAME IS NULL THEN 1 ELSE 0 end, a.JOB 으로 써주자.
*/
/*
SQL Server는 마지막에 Order by절을 바로 쓸 수 있지만 Oracle은 반드시 묶어줘야 한다.
구조상 웬만하면 묶어주는게 맞다.
*/
Cube
SELECT b.DNAME, a.JOB, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY CUBE(b.DNAME, a.JOB)
ORDER BY b.DNAME, a.JOB;
Cube는 Roll up과는 달리 인수로 지정한 모든 소계를 보여준다. (모든 경우의 수)
그리고 마찬가지로 마지막 행에 전체 합계 표시.
다음 쿼리를 풀어서 하면
SELECT * FROM (
SELECT b.DNAME, a.JOB, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY b.DNAME, a.JOB
UNION ALL
SELECT b.DNAME, NULL, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY b.DNAME
--+{
UNION ALL
SELECT NULL, a.JOB, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY a.JOB
--}
UNION ALL
SELECT NULL, NULL, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
)
ORDER BY DNAME, JOB;Grouping Sets
SELECT b.DNAME, a.JOB, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY GROUPING SETS(b.DNAME, a.JOB)
ORDER BY b.DNAME, a.JOB;
이번에는 조합 없이 지정한 컬럼 각각의 그루핑 된 합계를 보여준다.
다음 쿼리를 풀어서 하면
SELECT * FROM (
SELECT b.DNAME, NULL AS JOB, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY b.DNAME
UNION ALL
SELECT NULL, a.JOB, SUM(a.SAL) AS SAL FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
GROUP BY a.JOB
)
ORDER BY DNAME, JOB;
'자격증 > SQLD' 카테고리의 다른 글
| SQL가이드 요약: 과목 II SQL 기본 및 활용 - 1장 (2) (0) | 2022.09.06 |
|---|---|
| SQL가이드 요약: 과목 II SQL 기본 및 활용 - 1장 (1) (0) | 2022.01.21 |
| SQL가이드 요약: 과목I 데이터 모델링의 이해 - 2장 (0) | 2022.01.19 |
| SQL가이드 요약: 과목I 데이터 모델링의 이해 - 1장 (0) | 2022.01.19 |